

Файл robots.txt – это текстовый файл, который помогает поисковым системам понять, какие страницы вашего сайта они могут индексировать, а какие – нет. Использование файла robots.txt является важным элементом оптимизации поисковой системы (SEO) и помогает контролировать доступ поисковых ботов к различным страницам сайта. Это позволяет исключить из поисковой выдачи страницы, которые вы не хотите показывать или индексировать.
Основная цель файла robots.txt – сообщить ботам поисковых систем о том, какие части сайта они могут обходить, а какие нет. Он обычно помещается в корневой каталог вашего веб-сервера и доступен по адресу www.example.com/robots.txt. Файл содержит правила, которые указывают паукам, какие страницы и разделы сайта индексировать или проходить мимо. Несмотря на то, что файл robots.txt не является обязательным для сайта, его использование может значительно помочь в оптимизации поисковой системы и уверенном представлении вашего контента.
Важно понимать, что файл robots.txt не является способом скрыть содержимое сайта от поисковых систем. Он просто предоставляет рекомендации для работы ботам. Если информация о странице доступна где-то еще в Интернете, ее можно будет найти и индексировать, даже если в файле robots.txt есть запрет на индексацию этой страницы. Однако, использование файла robots.txt может помочь управлять процессом индексации и облегчить поисковым системам понять, какие страницы имеют наибольшую ценность для вашего сайта.
В этой статье мы рассмотрим основные способы использования файла robots.txt для оптимизации поисковой системы и расскажем о некоторых распространенных ошибках, которые следует избегать. Мы также рассмотрим некоторые примеры кода для правильного использования файла robots.txt и дополнительные инструменты, которые могут помочь вам в этом процессе.
Как использовать файл robots.txt
Для создания файла robots.txt вам необходимо открыть текстовый редактор и сохранить файл с именем «robots.txt». Затем вы можете разместить его в корневой директории вашего веб-сайта.
В формате HTML файл robots.txt имеет следующую структуру:
- User-agent: указывает на конкретного поискового робота, для которого предназначены следующие инструкции. Например, «User-agent: Googlebot» означает, что инструкции относятся к роботу Google. Если вы хотите указать инструкции для всех роботов, применяется значение «*», например «User-agent: *».
- Disallow: указывает на разделы сайта, которые необходимо исключить из индексации. Например, «Disallow: /private/» означает, что папка «private» и ее содержимое не должны быть индексированы.
- Allow: указывает на разделы сайта, которые необходимо индексировать, даже если другие инструкции указывают на их исключение. Например, «Allow: /public/» означает, что папка «public» должна быть индексирована, несмотря на наличие других инструкций.
- Sitemap: указывает на местонахождение файла карты сайта (sitemap.xml), который помогает поисковым системам более эффективно индексировать страницы вашего сайта.
Важно понимать, что файл robots.txt не является средством защиты конфиденциальной информации или ограничения доступа к страницам сайта. Поисковые роботы могут проигнорировать его инструкции, и веб-адреса, указанные в файле, всё равно могут попасть в результатах поиска.
Зачем нужен файл robots.txt
С помощью файла robots.txt можно ограничить доступ поисковых роботов к определенным разделам сайта, файлам или папкам. Например, если на сайте есть административная панель или другие конфиденциальные данные, то их можно исключить из индексации, чтобы не отображать их в результатах поиска. Это особенно важно для сайтов, которые требуют авторизации или содержат информацию, доступ к которой должен быть ограничен.
Инструкции в файле robots.txt

В файле robots.txt используются различные директивы, которые устанавливают правила для поисковых роботов. Например, директива «User-agent» указывает на то, для какого поискового робота задаются правила, а директива «Disallow» сообщает роботам, какие разделы или файлы сайта они не должны сканировать и индексировать.
Также в файле robots.txt можно указывать расположение файла карты сайта, чтобы облегчить доступ поисковым роботам к содержимому сайта. Это особенно полезно для больших сайтов с множеством страниц, так как позволяет ускорить процесс индексации и обновления результатов поиска.
Как создать файл robots.txt
Для создания файла robots.txt в формате HTML необходимо открыть любой текстовый редактор и сохранить файл с расширением «.txt». Далее нужно добавить необходимые директивы, которые будут указывать поисковым роботам, что им можно и что нельзя индексировать на сайте.
Заголовок User-agent: указывает на тип поискового робота. Можно указать конкретного робота, например, User-agent: Googlebot, или использовать символ «*» для указания общих правил для всех роботов.
Далее следуют директивы, которые определяют, что делать с определенными страницами или директориями сайта. Например, Disallow: указывает на запрет индексации определенного URL, Allow: разрешает индексацию определенного URL.
Примеры:
- Disallow: /private/ — запретить индексацию всех файлов и директорий, находящихся внутри папки «private».
- Disallow: /secret-page.html — запретить индексацию конкретной страницы «secret-page.html».
- Allow: /public/ — разрешить индексацию всех файлов и директорий, находящихся внутри папки «public».
После создания файла robots.txt необходимо загрузить его на сервер сайта в корневую директорию. После этого файл будет считываться поисковыми роботами и использоваться для определения индексируемых страниц.
Структура файла robots.txt
Структура файла robots.txt достаточно проста. Он состоит из нескольких командных строк, где каждая строка представляет собой пару ключ-значение. Ключ определяет действие, а значение указывает на те URL-адреса, к которым оно применяется. Команды разделяются переводом строки.
Некоторые из наиболее распространенных команд в файле robots.txt:
- User-agent: указывает на имя поискового робота, к которому применяются следующие правила. Например, «User-agent: Googlebot».
- Disallow: говорит роботу не индексировать определенный URL-адрес или раздел сайта. Например, «Disallow: /private/».
- Allow: разрешает роботу индексировать определенный URL-адрес или раздел сайта. Например, «Allow: /public/».
- Sitemap: указывает путь к файлу карты сайта, который помогает поисковым роботам понять структуру сайта и обновленный список URL-адресов. Например, «Sitemap: https://www.example.com/sitemap.xml».
Важно отметить, что файл robots.txt является открытым документом, доступным для каждого, и не может полностью запретить индексацию страниц. Некоторые поисковые системы могут не учитывать указанные ограничения или игнорировать файл robots.txt вообще. Поэтому, при применении файла robots.txt необходимо учитывать особенности работы каждой конкретной поисковой системы.
Как указать директивы в файле robots.txt
Чтобы указать директивы в файле robots.txt, необходимо использовать определенный синтаксис. Каждая директива должна начинаться с пути (URL) или паттерна, за которым следует указание, разделенное пробелом. Одна строка файла robots.txt обрабатывается поисковым роботом от начала до первой пустой строки или комментария.
Директива «User-agent» указывает на конкретного поискового робота или группу поисковых роботов. Директива «Disallow» указывает на путь или паттерн, который не должен быть проиндексирован поисковым роботом. Директива «Allow» указывает на путь или паттерн, который должен быть проиндексирован, даже если есть другие директивы «Disallow».
Примеры директив в файле robots.txt:
- User-agent: *
- Disallow: /private/
- Disallow: /admin/
- Disallow: /cgi-bin/
- Allow: /public/
В данном примере директивы указывают, что любой поисковый робот с помощью символа «*» не должен проиндексировать пути «/private/» и «/admin/», но может проиндексировать путь «/public/». Таким образом, файл robots.txt позволяет вам контролировать, какие части вашего сайта должны быть доступны для индексации поисковыми роботами, а какие — нет.
Часто задаваемые вопросы о файле robots.txt
1. Что такое файл robots.txt?
Файл robots.txt является специальным текстовым файлом, который размещается на сервере и используется для указания поисковым роботам, какие страницы сайта они могут индексировать и сканировать, а какие страницы нужно исключить.
2. Где расположен файл robots.txt на сайте?
Файл robots.txt обычно находится в корневой директории сайта. Адрес файла можно найти, добавив к адресу домена «/robots.txt» (например, www.example.com/robots.txt).
3. Как создать файл robots.txt?
Чтобы создать файл robots.txt, нужно создать простой текстовый файл с названием «robots.txt» и сохранить его в корневой директории сайта. Затем внутри файла можно указывать директивы, которые определяют правила для поисковых роботов.
4. Какая структура имеет файл robots.txt?
Файл robots.txt состоит из правил, называемых директивами, разделенных на строки. Каждая строка может содержать две основные части: «User-agent» (определяющий поискового робота) и «Disallow» (указывающий запрещенные для индексации URL).
5. Как проверить файл robots.txt на ошибки?
Есть несколько инструментов, которые позволяют проверить файл robots.txt на наличие синтаксических ошибок. Например, вы можете использовать инструменты Google Search Console или онлайн-проверку файлов robots.txt, доступные на различных веб-сайтах.
- Однако, нужно помнить, что файл robots.txt не является абсолютной гарантией о том, что роботы поисковых систем будут следовать указанным правилам. Некоторые роботы могут проигнорировать инструкции файла robots.txt. Поэтому, использование файла robots.txt способствует, но не гарантирует, что определенные части сайта не будут индексироваться поисковыми системами.
Проверка и отладка файлов robots.txt
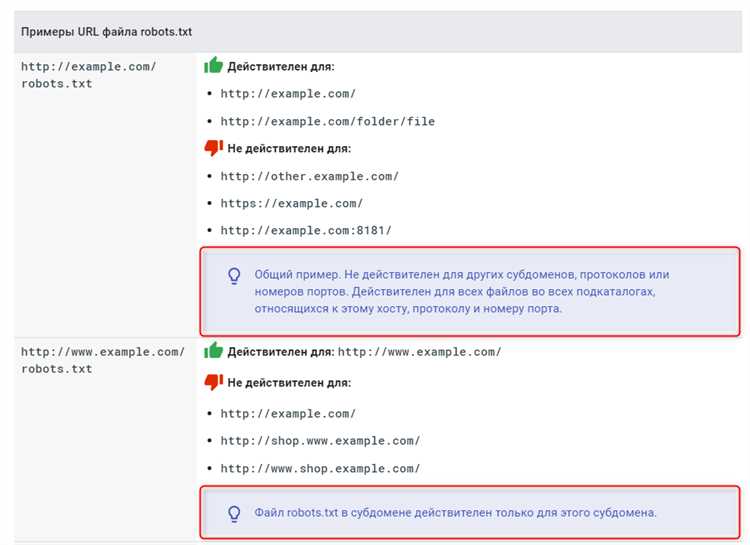
После создания файла robots.txt рекомендуется провести его проверку и отладку для обеспечения корректной работы и учета всех требований поисковых систем. Важно убедиться, что файл не содержит ошибок и правильно учитывает инструкции для роботов.
Использование инструментов проверки
Существует несколько инструментов, которые помогают проверить файл robots.txt на наличие ошибок и дополнительно отладить его:
- Google Search Console: этот инструмент позволяет загрузить файл robots.txt и просмотреть его содержимое после обработки Google. Он также предоставляет информацию о возможных ошибках и предупреждениях.
- Yandex.Webmaster: аналогично Google Search Console, Yandex.Webmaster позволяет загрузить и проверить файл robots.txt, а также получить информацию о проблемах, связанных с его содержимым.
- Robots.txt Tester вручную: третий вариант — использовать инструменты проверки файлов robots.txt, доступные онлайн. Они обычно предлагают возможность загрузить файл и выполнить тестирование на наличие ошибок.
При использовании инструментов проверки следует обратить внимание на следующие аспекты:
- Проверьте наличие ошибок синтаксиса: убедитесь, что файл записан в правильном формате и не содержит опечаток или неправильных символов.
- Удостоверьтесь, что инструкции для роботов указаны корректно: убедитесь, что указанные запреты и разрешения применяются к нужным страницам и содержат правильные директивы.
- Проверьте доступность разделов сайта для разных типов роботов: убедитесь, что разделы, которые следует скрыть от поисковых систем, действительно закрыты в файле robots.txt.
Итог
Проверка и отладка файлов robots.txt являются важным этапом процесса создания и оптимизации сайта. Тщательная проверка поможет выявить возможные ошибки и гарантировать корректное взаимодействие с поисковыми роботами. Используйте доступные инструменты проверки, чтобы удостовериться в правильности составления файла и соблюдении всех требований поисковых систем.